Web Scraping for (JS) Dummies
In the long and SOMEtimes coherent blog series below, I made a case against web scraping, when justifying why my Google Chrome Extension does what it does, the way it does (very little, but quickly, respectively. 😋)
However, I web-scrape almost daily; not as a recruiter, but as a sales helper, automating the influx of leads at the awesome place that is FusionWorks!
Due to my “90s Computing Mindset ™” (described here and there) I’m obsessed by optimization (even if apps run on superfast Cloud servers! 🤪) So I always web-scraped “the hard way”: manipulating the hell out of strings via JavaScript (almost a forced choice on Google Apps Script.)
But as I discovered a couple of times already, while this mindset is good for performance tuning, it can often prove to be overkill nowadays, as small speed differences are not noticeable on small workloads.
Nobody wants to tune a Toyota Prius for racing, at least nobody sane! 🤣
So I told myself: let’s see what the normal people are using, for once…
And now I’ll report what I learned in little more than 2 hours of deep dive, comparing stuff for your convenience… Or amusement!
The hard way: the (lovely) hell of string manipulation
While I see many don’t like JavaScript string manipulation, I find it fascinating, and much easier than the hell I remember from my self-taught C++ years (although I can’t be sure: it was almost 25 years ago! 🧓)

NOTE: This assumes no access to the DOM, because of environment constraints. It’s the worst-case scenario: treating pages as strings!
I went from “blunt force” splits, forEach cycles, and bad if/else’s (I had just started coding 😅) like this function for the extraction of keywords:
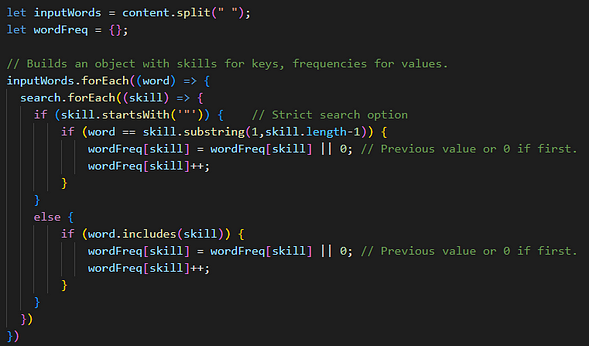
To the less “janky”, less nested, faster version here, using a Set for the dictionary and a for…of on it. Gained around 15% in speed!
(The additional stuff existed in some form in the previous one too, but I can’t be bothered to dig the old commits… 🤣)

… To working directly with indexOf and substring (in a different use-case.)
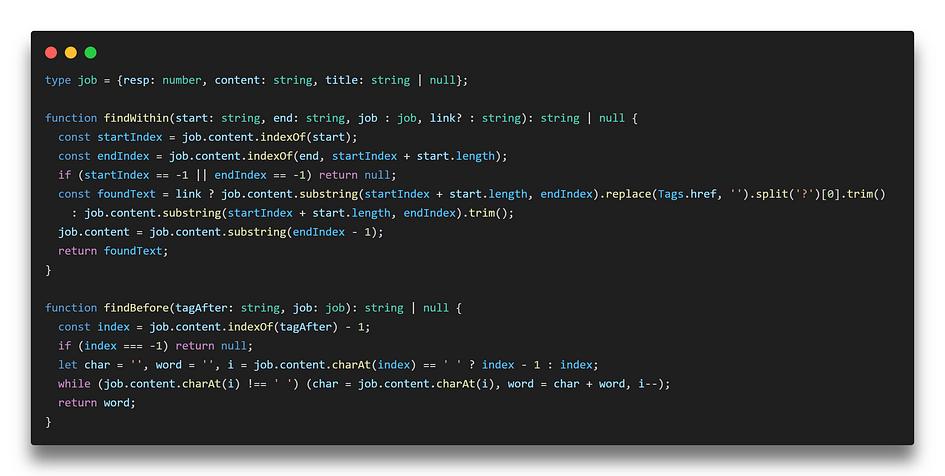
The difficult part here is understanding what works best when it comes to finding the HTML elements/attributes we need.
As I found out, it’s often not worth thinking too much about this stuff: whether you split everything and work on string arrays, use indexOf and substring, or do something more spLice-y (dev-dad joke 🧓) performance will be similar. E.g.: a version of the above using split got almost the same speed.
Speed is more influenced by loops, and where/how/when you store stuff.
I recommend using Map and Set objects when it makes sense, since they can be even faster than arrays when looking up stuff, or just being mindful of when you’re copying stuff, and when you’re just referencing objects.
About loops, more serious people than me found that the fastest is usually the classic for (bad for other reasons) or forEach, while “for in” and “for of” are usually slower, though the latter is amazing with Sets and Maps.
If like me you do this stuff from Google Workspace Apps, which run on GCP for free, you won’t feel much of a difference, so just go for what’s more readable for you, or if working in a team, what the team agrees is best! 👍
Cheerio: a library that makes things easier… Especially screwing up!
Yes, I didn’t become a fan of this cheerful library, at all…
I think it exists just to make jQuery veterans happy.
Performance is very similar to regular string manipulation (obviously, since that’s what’s under the hood), but you’ll find that any dynamic content that takes time to load on a page is totally out of reach for Cheerio, when even puny URLFetchApp on Google Apps Script can actually get it!
If like me you’ll look for a solution to this on Stack Overflow, you’ll find replies telling people to just stop using Cheerio, and use Puppeteer, instead! 🤣 (Which I did!)
To be sure, I also asked ChatGPT, and indeed it confirmed that dynamically-loaded content is not going to be seen by Cheerio. ⛔
I couldn’t believe this, so I tried introducing some artificial delay (after asking ChatGPT and being told it could solve this) but none of my or ChatGPT’s solutions actually worked. Thanks for nothing, AI! 😏

Puppeteer: now we’re talking! Unless you want to deploy for free…
Puppeteer is widely considered one of the best tools/frameworks to scrape the web using JavaScript, thanks to its headless browser approach.
This is what you want to use to actually interact with pages, for example logging into websites, or just waiting for content before extracting data.
I really liked Colby Fayock’s guide to deploy Puppeteer serverless.
But if you try the same now it won’t work because of dependencies’ versions conflicts, and an increase in size of chrome-aws-lambda plus puppeteer-core, above the memory limits of Netlify’s serverless Functions. (For once my 90s Computing Mindset ™ is relevant! 🤣)
You might have some luck if you use his exact same dependency versions…
But I didn’t try because I realized: I don’t need it hosted as an API! While it’d definitely be cool, I can actually just run it locally, and make it send data to a web app I already have online, like my own Google Apps Script!
You just need to deploy the Google Apps Script as a web app, open it up with a doPost, handle the requests, and do what you want with the data. 👍