In the long and SOMEtimes coherent blog series below, I made a case against web scraping, when justifying why my Google Chrome Extension does what it does, the way it does (very little, but quickly, respectively. 😋)
However, I web-scrape almost daily; not as a recruiter, but as a sales helper, automating the influx of leads at the awesome place that is FusionWorks!
Due to my “90s Computing Mindset ™” (described here and there) I’m obsessed by optimization (even if apps run on superfast Cloud servers! 🤪) So I always web-scraped “the hard way”: manipulating the hell out of strings via JavaScript (almost a forced choice on Google Apps Script.)
But as I discovered a couple of times already, while this mindset is good for performance tuning, it can often prove to be overkill nowadays, as small speed differences are not noticeable on small workloads. Nobody wants to tune a Toyota Prius for racing, at least nobody sane! 🤣
So I told myself: let’s see what the normal people are using, for once… And now I’ll report what I learned in little more than 2 hours of deep dive, comparing stuff for your convenience… Or amusement!
The hard way: the (lovely) hell of string manipulation
While I see many don’t like JavaScript string manipulation, I find it fascinating, and much easier than the hell I remember from my self-taught C++ years (although I can’t be sure: it was almost 25 years ago! 🧓)
NOTE: This assumes no access to the DOM, because of environment constraints. It’s the worst-case scenario: treating pages as strings!
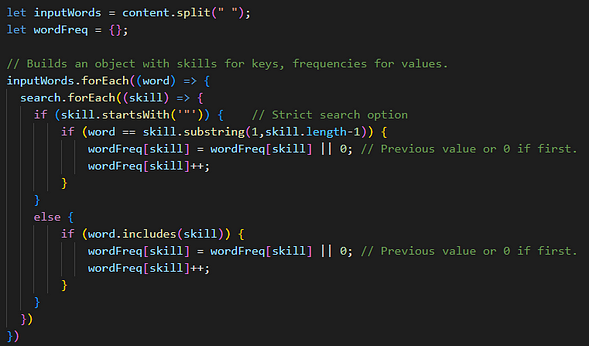
I went from “blunt force” splits, forEach cycles, and bad if/else’s (I had just started coding 😅) like this function for the extraction of keywords:
To the less “janky”, less nested, faster version here, using a Set for the dictionary and a for…of on it. Gained around 15% in speed! (The additional stuff existed in some form in the previous one too, but I can’t be bothered to dig the old commits… 🤣)
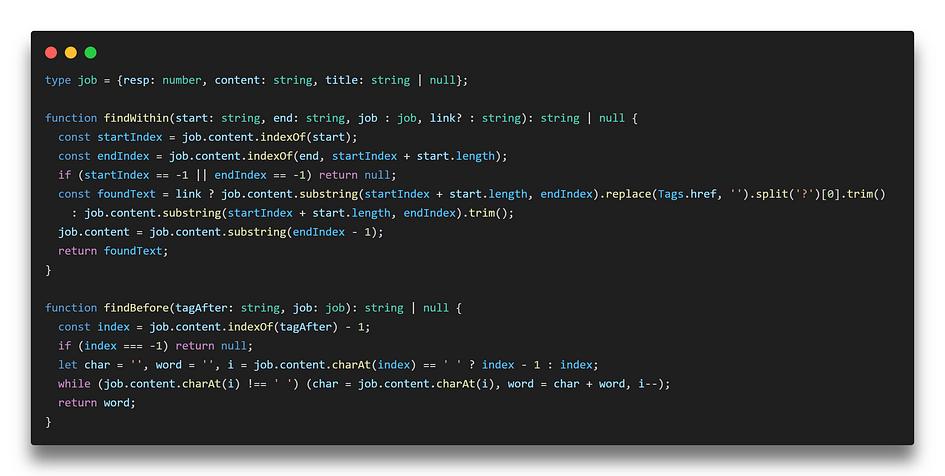
… To working directly with indexOf and substring (in a different use-case.)
See what you lose chasing performance…?
The difficult part here is understanding what works best when it comes to finding the HTML elements/attributes we need.
As I found out, it’s often not worth thinking too much about this stuff: whether you split everything and work on string arrays, use indexOf and substring, or do something more spLice-y (dev-dad joke 🧓)performance will be similar. E.g.: a version of the above using split got almostthe same speed.
Speed is more influenced by loops, and where/how/when you store stuff.
I recommend using Map and Set objects when it makes sense, since they can be even faster than arrays when looking up stuff, or just being mindful of when you’re copying stuff, and when you’re just referencing objects.
About loops, more serious people than me found that the fastest is usually the classic for (bad for other reasons) or forEach, while “for in” and “for of” are usually slower, though the latter is amazing with Sets and Maps.
If like me you do this stuff from Google Workspace Apps, which run on GCP for free, you won’t feel much of a difference, so just go for what’s more readable for you, or if working in a team, what the team agrees is best! 👍
Cheerio: a library that makes things easier… Especially screwing up!
Yes, I didn’t become a fan of this cheerful library, at all…
I think it exists just to make jQuery veterans happy. Performance is very similar to regular string manipulation (obviously, since that’s what’s under the hood), but you’ll find that any dynamic content that takes time to load on a page is totally out of reach for Cheerio, when even puny URLFetchApp on Google Apps Script can actually get it!
If like me you’ll look for a solution to this on Stack Overflow, you’ll find replies telling people to just stop using Cheerio, and use Puppeteer, instead! 🤣 (Which I did!)
To be sure, I also asked ChatGPT, and indeed it confirmed that dynamically-loaded content is not going to be seen by Cheerio. ⛔
I couldn’t believe this, so I tried introducing some artificial delay (after asking ChatGPT and being told it could solve this) but none of my or ChatGPT’s solutions actually worked. Thanks for nothing, AI! 😏
So funny! 🤣 In the end it’s “Just use Puppeteer”, like Stack Overflow’s repliers…
Puppeteer: now we’re talking! Unless you want to deploy for free…
Puppeteer is widely considered one of the best tools/frameworks to scrape the web using JavaScript, thanks to its headless browser approach.
This is what you want to use to actually interact with pages, for example logging into websites, or just waiting for content before extracting data.
I really liked Colby Fayock’s guide to deploy Puppeteer serverless.
But if you try the same now it won’t work because of dependencies’ versions conflicts, and an increase in size of chrome-aws-lambda plus puppeteer-core, above the memory limits of Netlify’s serverless Functions. (For once my 90s Computing Mindset ™ is relevant! 🤣)
You might have some luck if you use his exact same dependency versions…
But I didn’t try because I realized: I don’t need it hosted as an API! While it’d definitely be cool, I can actually just run it locally, and make it send data to a web app I already have online, like my own Google Apps Script!
As an HR Professional with a strategic mindset and 9+ years of experience in this mysterious field, one of the most important aspects of my team’s job is to ensure that we have the best talent available for our organization. In today’s digital age, when everything is changing so fast, the reality of work has changed as well, and hiring dedicated skilled freelancers has become a popular choice for businesses. In this article, I will highlight the advantages of working with dedicated skilled freelancers who have been selected by a team specially tailored to your organization’s needs, along with a solution that may save you time and money.
“A stress-free way to hire tech teams” — Talents.Tech
Advantage Nr.1 — Flexibility to scale your workforce up or down based on your business needs. This means that you can easily tap into a pool of talent who are readily available to work on your projects, without having to worry about overhead costs such as office space, benefits, and training expenses. In addition, the ability to scale your workforce means that you can easily adapt to changing market conditions or project demands.
Advantage Nr.2 — Bring a wealth of expertise and experience to your organization. By working with a team that has been specially selected for your needs, you can be assured that they have the right skills, knowledge, and experience to deliver quality work. This means that you can tap into a pool of talent that has already been vetted and evaluated, which saves you time and resources in the recruitment process.
Advantage Nr.3 — Opportunity to tap into a global talent pool. This means that you can access talent from different parts of the world, who bring unique perspectives and skills to the table. By working with a diverse pool of talent, you can analyze their different backgrounds and experiences to create innovative solutions for your organization.
Advantage Nr. 4 — Long-term relationships with your talent pool. By establishing ongoing relationships with your freelancers, you can build trust and loyalty, which translates into a stronger and more productive workforce. This means that you can tap into a pool of talent that is committed to your organization’s success, and who is willing to go the extra mile to ensure that your projects are delivered on time and within budget.
Did you know that Talents.Tech works in just 4 easy-steps?
(1) The client submits a request
(2) AI algorithms select a list of suitable profiles
(3) The client chooses a candidate from this list
(4) Work Starts
When a company chooses to work with a freelancer, there are a number of potential challenges they may face. Here are some of the most common problems a company may encounter when choosing to hire a freelancer:
a) Finding the right candidate: This requires a deep understanding of the job requirements and a thorough screening process to identify candidates who possess the necessary skills, experience, and cultural fit.
b) Time constraints: Companies often have to work within tight deadlines and face pressure to fill job vacancies quickly. This can be particularly challenging when there are multiple positions to fill simultaneously.
c) Quality control: It can be difficult to ensure consistent quality when working with freelancers, especially if they have different work styles or standards than your company.
d) Communication: This can be more difficult with freelancers, as they may not be as readily available for meetings or check-ins.
e) Accountability: Because freelancers are not full-time employees, they may not feel as invested in the project or company, and may not take accountability as seriously as an employee would.
f) Dependability: Freelancers may have other clients or commitments that take precedence over your project, making it difficult to rely on them for timely delivery.
g) Cost: While hiring a freelancer can be more cost-effective in the short term, it may end up costing more in the long run if the work is not up to standard, or if you have to continually hire new freelancers to replace those who do not work out.
Talents.tech was specifically designed to address these real problems that companies face when working with freelancers. They understand that finding the right talent can be a time-consuming and costly process, especially when you’re trying to build a team that’s tailored to your organization’s specific needs.
Our partner’s platform was created to help companies overcome these challenges by providing a curated pool of talented and skilled freelancers interviewed and tested by a team of experts in their respective fields. AI algorithms select the best from the best and propose you a list of profiles that are suitable for your own project. This means that you can be assured that the freelancers you work with have the right skills and experience to deliver quality work on time and within budget.
Along with these, their platform is designed to offer companies the flexibility and scalability they need to adapt to changing business needs. Whether you need to scale your workforce up or down, our platform makes it easy to find the talent you need, when you need it.
Why work with Talents.tech? Professionally screened candidates. The vast range of specialists. Small service fee.
In conclusion, working with dedicated skilled freelancers who have been selected by a team specially tailored to your organization’s needs offers a range of advantages, including flexibility, expertise, global reach, and long-term relationships. By pointing out these advantages, your organization can tap into a pool of talent that is committed to your success and who can deliver quality work on time and within budget. Talents.tech is the answer to the real problems that companies face when working with freelancers. They provide a simple and effective solution that saves time, reduces costs, and ensures that you work with the best talent. Being a huge part of the HR team, I recommend that organizations explore the benefits of working with dedicated skilled freelancers that were selected especially for their needs and projects. As there is no bad or good professional, there are just collaborations that can not succeed without dedicated magic, present during the recruiting process. In our case — this is done by the harmony between human proficiency and AI correctness.
If all these arguments are not enough and you still want to work and collaborate with ”sweet outsourcing”, feel free to contact our trusted team at FusionWorks. As we know how to build your product from scratch or join the existing team as we are TECH-ORIENTED. PEOPLE-CENTRIC. LEARNING-DRIVEN.
As the freelance workforce continues to grow, companies are increasingly relying on freelance talent to meet their business needs. While hiring freelancers has many benefits, such as cost savings, flexibility, and access to specialized skills, it also comes with its own set of risks.
As an HR specialist with 9 years of experience, I’ve seen firsthand the challenges that companies face when it comes to hiring freelance talent. In this article, I’ll share some best practices and strategies to help companies minimize the risks associated with freelance talent acquisition.
Looking for your next employee? Fill in a form here and the magic will start.
Clearly Define Project Scopeand Expectations— one of the biggest risks when hiring freelancers is the lack of clarity around project scope and expectations. To limit this risk, it’s important to clearly define the project scope and expectations upfront, including deliverables, timelines, and communication protocols. This will help ensure that the freelancer understands what is expected of them and can deliver the project on time and within budget. If you need help here, feel free to contact FusionWorks, as one of their directions is consulting.
Conduct a Thorough Screening Process — when hiring freelancers, it’s important to conduct a thorough screening process to ensure that they have the necessary skills and experience to complete the project successfully. This may include reviewing their portfolio, checking references, and conducting interviews to assess their communication and collaboration skills. No need to hire expensive consultants, start using Talents.Tech.
Use a Contract or Statement of Work — to protect both parties, it’s important to use a contract or statement of work that clearly outlines the terms of the project, including payment, intellectual property rights, and termination clauses. This will help ensure that both parties are on the same page and can avoid any misunderstandings or disputes down the line. You may hire a legal consultant here, in order to draft all needed documents once and you may use them happily after.
Set Clear Performance Metrics — to ensure that the freelancer is meeting expectations and delivering high-quality work, it’s important to set clear performance metrics upfront. This may include deadlines, quality standards, and communication expectations. Regular check-ins and performance reviews can help ensure that the freelancer is meeting these metrics and can help identify any issues early on. Setting clear and correct key metrics is crucial for any organization that wants to succeed, if you need any help here, contact FusionWorks as they always have the solution to your needs.
Build Strong Relationships with Freelancers — building strong relationships with freelancers can help minimalize the risk of turnover and ensure that the freelancer is invested in the success of the project. This may include regular communication, recognition of their contributions, and opportunities for professional development.
In conclusion, hiring freelancers comes with its own set of risks, but by following these best practices and strategies, companies can proactively approach in order to minimize these risks and ensure the success of their freelance talent acquisition efforts. By clearly defining project scope and expectations, conducting a thorough screening process, using a contract or statement of work, setting clear performance metrics, and building strong relationships with freelancers, companies can reap the benefits of the freelance workforce while minimizing the risks.
Additionally, companies can make the process of hiring freelancers even easier by choosing a suitable platform for their needs. One option is a worldwide staffing and recruitment platform that connects businesses with technical teams, providing a stress-free way to hire tech teams and ensure a positive experience while having a productive collaboration with freelancers. By utilizing a platform that offers pre-screened talent, companies can reduce the risk of miscommunication and ensure a successful project outcome.
Another solution here is to forget about freelancers from all over the world and to continue working with outsourced teams. Choose your partner taking into consideration their expertise, portfolio, and of course — other reviews.
Finally reaching the end of this 1–2–and now-3-part series! Or am I..?
Thanks to the great learning opportunities at FusionWorks, even a lowly tech recruiter like me has lots of coding stories to tell, but the question is: are they entertaining for peopleother than the 2 or 3 inside my head? 😂
This time, thanks to the omnipresence of Chat-GPT in my (and many others’) workflow, I think I got a funny story, of which I’ll spoil the conclusion right away: developers, software engineers, or however else “coding people” self-define, are still not going to be replaced anytime soon! 🥳
DISCLAIMER: Like crypto-bros say “don’t take this as financial advice” I’ll say “don’t take this as coding advice”! I’m a tech recruiter, not a developer! 😁
A bit of context/recap!
Finally reaching the end of this 1–2–and now-3-part series! Or am I..?
Thanks to the great learning opportunities at FusionWorks, even a lowly tech recruiter like me has lots of coding stories to tell, but the question is: are they entertaining for peopleother than the 2 or 3 inside my head? 😂
This time, thanks to the omnipresence of Chat-GPT in my (and many others’) workflow, I think I got a funny story, of which I’ll spoil the conclusion right away: developers, software engineers, or however else “coding people” self-define, are still not going to be replaced anytime soon! 🥳
DISCLAIMER: Like crypto-bros say “don’t take this as financial advice” I’ll say “don’t take this as coding advice”! I’m a tech recruiter, not a developer! 😁
A bit of context/recap!
My Chrome Extension grew almost exponentially since last time we “spoke”, at least in my perception… For the world outside of my head, it’s still quite a simple app that scrapes data and sends it to a Google Apps Script web app I also wrote, which in turn writes it on a Google Sheet.
A well-thought-out extension would surely be able to do all this without the intermediary, but I prioritized speed, or better yet EASE of learning.
A rather accurate diagram of my Chrome Extension coupled with my Google App Script App! 😁
Still, whenchoosingeasypaths, one sometimes ends up doing morework…
For example, it’s not comfortable to maintain 3 different codebases for what is essentially a mass structured copy-pasting, but it’s also conceptually much easier than creating a monolithic app (and anyway the 3rd codebase, the scripted part of the destination Google Sheet, would not be avoided.)
A story within the story (⏩Skip if not into coding!)
New things included a massive refactoring to an async–await pattern I finally decided to learn, replacing nested callback functions which i used to like, and now see ugly as hell! 😂
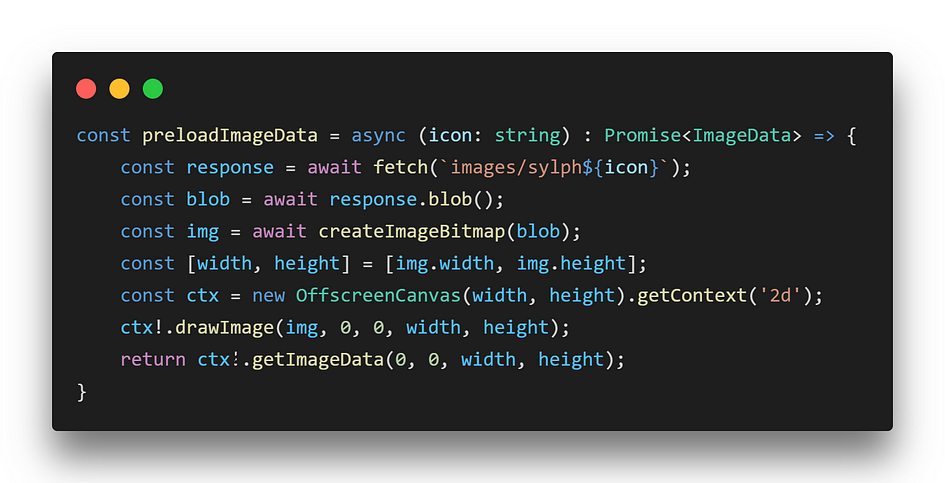
This is also used to preload imageData for the waiting animation, and this part sparked quite a debate online, for my usage of forEach with async…
While not directly related to the main story, which has to do with CRUD operations on Google Sheets, coding-wise both issues have to do with how arrays work in Java/TypeScript: again, DOSKIP this if not into coding!
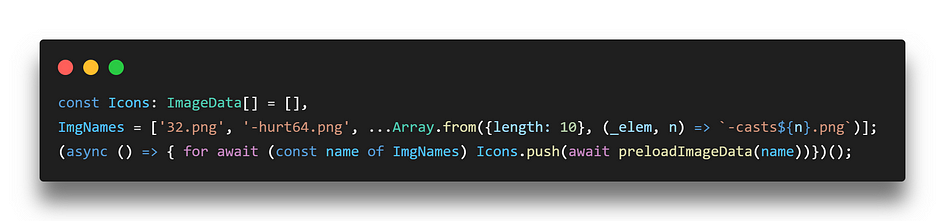
Notice also the fancy way of entering 10 similar filenames into ImgNames: hot or not? 🤔
The question about this code was: will Icons[] be ordered like ImgNames[]?Yes, because even if the promises all fulfill at different times, the array positions the data will fill in the array are explicitly referenced by index.
I get this is not considered good practice, and probably hard to test, but the thing is many more elegant solutions are forbidden in the context! 🤔
First of all, we can’t really draw image elements here, because this is the Service Worker part of the extension, so it has no page/DOM of its own.
This is another context in which ChatGPT could help very little, but I’ll digress…
Second, it can’t use modules or be a module of its own (a recent Chrome update has introduced the possibility, but requiring quite a few systemic change I didn’t yet want to commit to), so “top-level awaits” are not allowed.
An alternative is to use this (IMO ugly) thing called IIAFE (Immediately Invoked Asynchronous Function Expression) to go around the above limitation, by encapsulating the “await” while still executing it right away.
I tested both and didn’t notice any changes, but I’ll be welcoming comments on what you think about this coding debate! 🧑💻💭
The actual story: FAST remote I/O on Google Sheets!
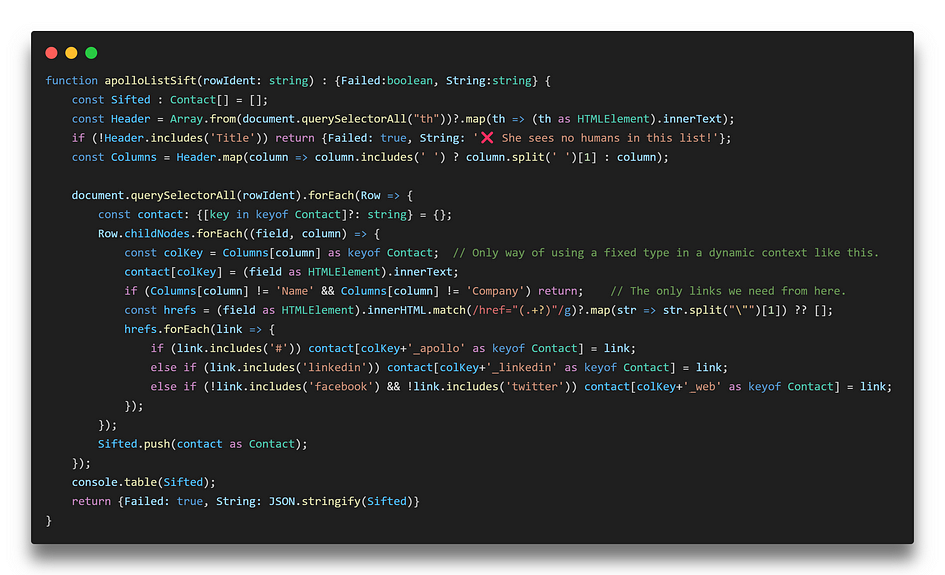
Finally getting to the heart of the topic, the extension now (finally) works using the POST method to communicate with the Google Apps Script part, and that was actually a necessity, since now it can get 25 contacts at a time, and the URL would have gotten extremely big if sending data via GET…
What it does is filling in a custom contact type procedurally, in a typical double-loop fashion going through rows and columns of the table.
The way it manages this neatly is by giving the type definition the same keys as the column titles on the page. Plus a lot of typecasting to force things a bit, which might mean TypeScript is a bit wasted here? 🙄 Let me know!
I know it returns a Failed state and a string instead of an object, but I won’t get into why it does that! 😂
The receiving end is where the story lies. It divides incoming contacts into new or existing, adding or updating accordingly. While this may seem the easiest thing in the world, doing separate I/O operations for each entry would (and did) take FOREVER, even if we’re talking only 25 contacts at a time.
This is due to the positioning of RichTextValues in relation to ones that can’t be RichText on the Google Sheet, and how GAS forces writes to be only in contiguous ranges. It meant 4 writes per contact, if done one by one! 🙈
But something you learn of Google Sheets scripting, is that it’s faster to rewrite THOUSANDS of rows in one go, than 10 rows in separate calls!
So to make sure these 25 updates would be done in a short amount of time, I realized I should have adapted to Google Sheets’ ways, the hard way:
Instead of having values that can’t be RichText in-between values that are, forcing me to differentiate the ranges to read and write the data, have all RichText values as close as possible (fortunately this meant just moving a hyperlink to another column, without changing the content.)
Instead of writing each line separately, process everything in the arrays, then write all lines, INCLUDING those not updated if they are in-between updated ones, so only 2 I/O operations are done respectively for adds and updates: 1 for normal and 1 for RichText.
This could lead to a total of 4 I/O operations from a previous total of 4 ops for all new plus 4 for each updated, so down from 52 on an average of half-new half-updated, or down from 100 if all needed to be updated! 🤯
Me when I realized this!!
Granted, the operations are bigger than before, especially if by chance the contacts to be updated are separated by thousands of rows, but wait and see the performance gains I got, after hoops and hooks with our beloved…
Chat-GPT: endless source of (ridiculous) solutions!
I had several theories on how to approach the problem, and as is usual for a noob like me, I went with the most complicated/stupid approaches first…
At one time for example, I had row numbers written within the raw data, just to be able to find them when the object was “flattened” to the actual fields I needed, so I had to slice out the row number before writing… 🥴
Although performance was not so bad (was still much better due to I/O reduction), it was such a shameful repetition: I already had the row numbers from the first division of new VS existing contacts, so why again?
The problem looked “geometrically” as follows: taking data from a 25-rows 2D array with row numbers, and use it to replace 25 rows within another 2D array of up to 3000 rows, without obvious row numbers… (Obvious 😏)
Asking solutions to Chat-GPT, I got answers that were incredibly weird…Here is a first reply about how to find the start and end row in the first place, which was suggested as a giant array reducing.
I thought it was a waste, and though I couldn’t pinpoint why right away, I proposed thisONE-LINE solution to ChatGPT, asking if it wasn’t better.
ChatGPT admitted it was better, but it noted it could have been slower or more memory consuming for large arrays (25 rows definitely isn’t big.)
Now I wanted to avoid a find on each iteration, although ChatGPT didn’t find it problematic. When prompted, it suggested a lookup object like this:
While it may seem more “elegant”, I still felt like both me and the AI were overlooking a MAJOR way of simplifying the whole problem. It wasn’t about wrong answers, but wrong questions.
The right question was: why mapping 1000s of rows to change 25, instead of going through the 25, and updating only those? Execution time was ok, but my frugal 90s Computing Mindset ™️ was SHOUTING it was a waste! 😣
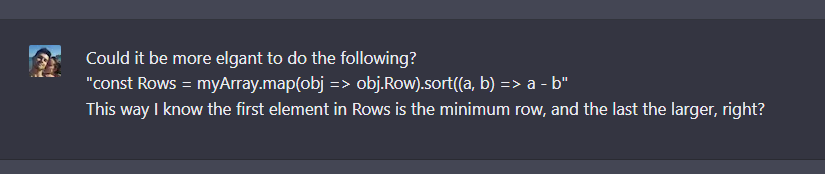
I was slowly catching up to the solution, but the AI didn’t help: when I pointed the issue, it proposed a puzzling double-counter tracking system…
Note the “assumption” it admits at the end: if that would be the case we wouldn’t have a problem, genius! 😂
Here it dawned on me: I already had a list of row numbers mapped in the same order as the data source: what stopped me from just changing the entries from the source, and then writing the updated array?
Nothing! Just my slow mind, and an AI that can’t think creatively!
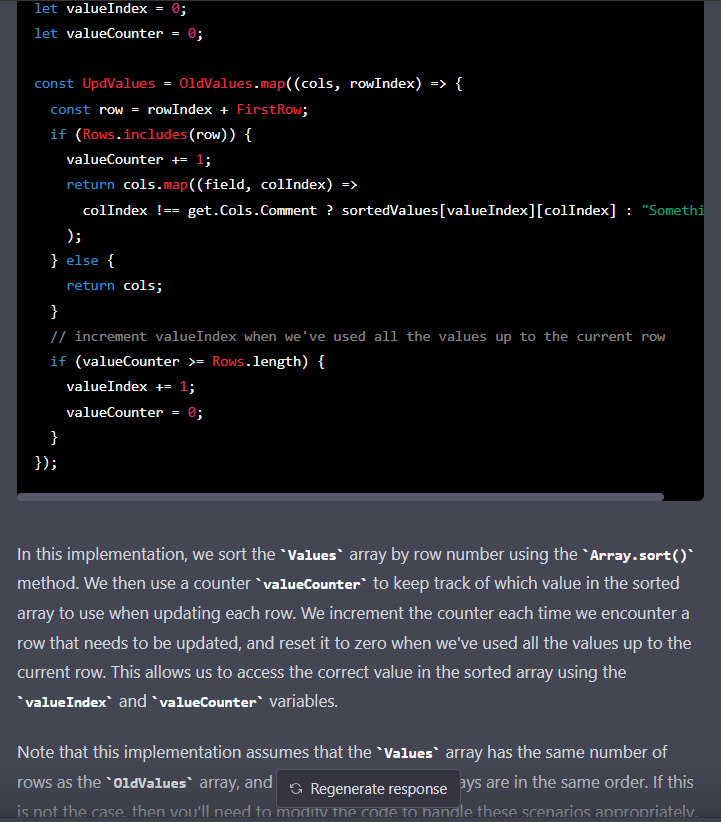
So here’s the super-simple solution I should have thought before…
The trick was once again to think about array positions: since I already had an array of row numbers in the same order as the incoming contacts (created to find the first row to update, as seen above), all I needed was to subtract the value of firstRow from each row, and I had the position in the slice of sheet I was considering, starting from 0 as it should be! 😅
Now using this it takes around 5 seconds to do everything, while before it could be between 12 and 25. Saving up to 80% of the time is BIG! 🥳
The main loop, with my long lines, comments, and all… Hope it’s readable! 😅
Conclusions: we’re STILL SAFE from AI overlords! 😁
And there was not much creativity involved here: it was actually the kind of stuff I expected the AI to shine on, so just imagine the mess on real issues!
Plus, as stated by the blogger above, another point to consider is how much time one can LOSE by using Chat-GPT: we will want to try the solutions it proposes, and more often than not it will result in wild goose chases..! 🦆
Conclusion: use Chat-GPT, but only for very, very simple tasks, asking extremely clear and limited code snippets, just to speed up your writing.
But when it comes to real problem solving: DON’T EVEN! 😂
Delve into the rest of my coding journey at FusionWorks, in the articles below!
Recruiter Codes Chrome Extension: pt.1, pt. 2 (Google Chrome TypeScript)
Dependencies are often treated lightly, and few ever consider the risks introduced to the project with every new library you may want to use.
Do you need a lib for it?
According to studies, over 90% of the code in our projects comes from libraries.
The upside is that this removes from you the burden of implementing big, complex systems because someone has already done that before you. On the other hand, 90% of the time you have no idea what’s happening inside your project during runtime, so you lack control over things you are liable for.
Of course, things aren’t as scary as I am putting them here, but I still believe that we should be aware of what we are dealing with.
Obviously, there is no point in us reinventing the wheel, so we depend on dependencies. Still, we should take some precautions. We’ve summed up some things you might want to consider when you need to integrate someone else’s work into yours:
Think of the value the new library brings to your project.
Discuss with your team the problem you are trying to solve and consider and compare alternative solutions. Decide if it’s a viable solution to bring a new tool for the job, or if you’d get by with an in-house solution.
In bigger projects, it is often a problem when similar problems have already been resolved by other project contributors and a fitting library is already installed. Check your project’s codebase for similar problems. You may be surprised and might even save some time.
Assess the library’s credit of trust.
When considering a new tool, study the community’s opinion on it. It should give you an impression of how well it does its job, but also what new issues and overhead it might introduce.
Check the library’s issue tracker, see how well it is supported, and observe the communication between issue reporters and code maintainers. You’ll want to avoid solutions that have an unpredictable or stagnant release cycle, unaddressed questions in issue threads, tiny communities lacking experience in their niche, documentation composed of a few usage examples, and an undocumented API.
The dangers of Open Source
While open-source sounds like a great idea to many enthusiasts because it is maintained by the entire community, the reality is that this ecosystem is very vulnerable to the mistakes of lone individuals (an infamous example).
Security implications
Depending on open source software means you lose control over a critical chunk of your project, and, in the most optimistic case, it means you might get a hard-to-catch bug. In the worst case scenario, you’ll introduce a security vulnerability and your entire production infrastructure will fall prey.
It is a misconception that open source is safe because everyone can review the code and projects are being maintained by groups of individuals with no commercial interest in the project’s path. Reality is different. Usually, most libraries in your projects are rarely maintained (during free time) by the solo efforts of individuals who have just decided to publish their personal tools. And these libraries, in their turn, depend on other libraries, again with variable levels of quality.
Another thing to consider when you decide to use a library is how well it controls its dependencies’ versioning. As it was mentioned before, libraries usually depend on other libraries, and that might become an issue if they do not manage their versions well.
When you install a new library, dependency managers in most programming languages follow the SEMVER versioning pattern, which allows flexible version ranges for your libraries. Many small libraries use ranged versions of dependencies rather than fixed versions. This, potentially, creates an avalanche of bugs in case just one of the dependencies in that tree fails after a minor patch. This kind of situation has occurred multiple times throughout the open-source software development history.
This creates the situation where your project may fail with no obvious reason the next time you clone it from the repo and sync the dependencies.
#ItWorksOnMyMachine
Most dependency managers create a lock file when you install a library. Many of us ignore it, some of us even .gitignore it, but let’s make it clear why it needs to exist in your repo.
When you install your libraries, your dependency manager resolves all the shared libraries, builds a dependency tree, and finds compatible dependencies to download and store. This information contains fixed versions, which should work on every machine if it works on yours.
Why do we need this? When the time comes and we have to publish our efforts to production, usually a Continuous Integration system takes over our code, clones it, syncs the dependencies, builds everything, and… fails with some version mismatch. You’ll be lucky if it fails during build time and not in runtime.
The lock file allows the CI to install exactly the same versions you had in working condition on your machine.