Tech Recruiter Tries Coding pt. 3— More GAS and DB-fication of sheets!
SEQUEL IS OUT! Recruiter Codes Chrome Extension — A LinkedIn Fairy(-tale)!
In part 2 of this growing (and growingly wordy) series, I talked about how to database-ify and CRM-ify spreadsheets, and a few things about how to code this stuff, elaborating on the basics described in part 1.
But when it came to actual code examples, I switched to a different topic.
This is because I didn’t want to bore you to death with routine stuff like indexing, managing of doubles, and such. 🥱
Trying to keep this merciful objective in view(!), l will try to re-take the subject and talk about some of this stuff, hoping to give good examples of the additional power of GAS (Google Apps Script)-powered spreadsheets over a database or a CRM (which, I love to say, is just a database frontend.)
So I will start with a few basics, without too much code, and then dive into a couple of code examples for the functions that I had more fun coding.
Basic steps to become a heretic DB-fier of spreadsheets
Now, I know I’m making you picture in your mind a lot of stuff since last time: it’s because if I would show you the actual spreadsheet, I’d have to transform it into a rave of censoring-happy emojis!
But you can imagine that managing double entries is quite easy, once everything has a unique ID.
Since all of our entries/rows are associated with at least one URL (if not an Email address, which is unique by definition), what I did was building a function that “sanitizes” the URLs by cutting out anything that can vary, keeping only the unique part, to avoid “false doubles” when the same URL is saved with different parameters or slashes, due to different sources, etc.
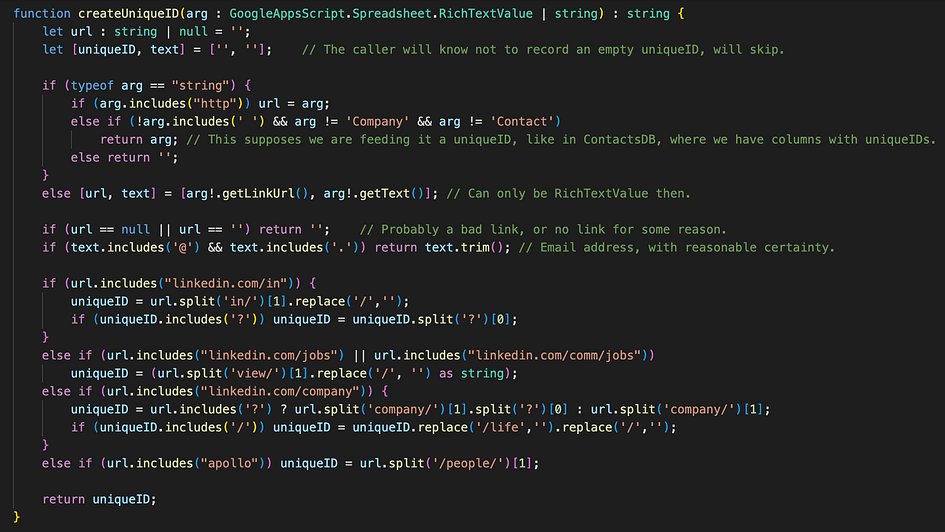
Checking for doubles is not interesting at all, save for one nice thing to make searches much faster: using GAS’s Properties Service to keep a reasonably updated list of unique IDs and something more, always ready to use, instead of getting it from the sheet all the time, which is much slower.
Functions that create indexes of uniqueIDs (thus finding double entries) and read/store them with Properties, can be automatized easily with the time-driven triggers that GAS kindly offers, to run at specified times.
Just make sure you set them at times you’re less likely to do changes yourself, especially if you schedule double deletion, that removes rows from the spreadsheet: I learned the hard way! 😅 (Thanks to the Version History feature of Google Sheets, nothing is ever lost anyway, but still…)

An interesting thing about running this stuff automatically, is that you’ll want some reporting/notification system that doesn’t use the UI, right? … Right?

Here’s the thing: alerts, dialogs, etc. won’t work in triggered scripts.
Google will actually prevent the whole script from running if it detects any, and for good reason: imagine discovering you lost tons of writing/editing, because a script started running in the meantime, and opened a pop-up..!
Therefore, to have time-triggered scripts report to you, you could set:
- Email notifications from GAS itself (but this won’t report anything custom, it will just tell you if an execution ends because of errors.)
- Custom emails that you send to yourself, from your own scripts.
- Actually outputting on the sheet, though it better be in frozen cells.
- A separate web service to check the status of stuff.
For me, receiving extra emails is always bad, and outputting on the spreadsheet too, since it’s slow, forces me to dedicate “real estate” of the spreadsheet to this, and it also updates the sheet window/view when formatting is involved: not nice if I’m editing stuff in that moment.
So, since I had built a GAS web service for something else before, I was close to building one for this purpose as well, when I realized a simpler solution: we can use sheet names/tabs for reporting!
I built a small function for this, just to take care of doubles, and it’s a joy to see it at work, but the potential is even bigger!
It could be used as a dynamic warning sign for when other time-driven scripts are running, or to give dynamic tips… It can almost be animated, although slowly and only through text, emoji, and a single bar of color.
It’s basically a piece of the UI that, since it doesn’t receive frequent input from the user, has been left open even for time-triggered scripts to use.
It’s such a nice backdoor, that we better not spread the word about it, or Google might change the rules!🤫
There are a lot more related topics, some big and some small, but I think these were the most-interesting, among the ones I can show.
I encourage you to discuss the topic in the comments, or, if you’d like a full-fledged system of this kind, just contact me or FusionWorks about it!
Next, we dive into some code to see how to deal with entries that are not exactly doubles, but that should not be on separate entries either… A very specific case : separate job posts for the same jobs!
“The Piggyback”… GAS + conditional formatting!
Very often, companies will post the same jobs multiple times, so you will have the same title but different URLs: replicas of the same job, maybe for different countries, or more often just for added visibility.
These are important for Lead Generation since in sales-talk they’re additional “buyer intent data”. So keeping them separate, other than being a potential source of errors or double work for Lead Generators, is bad from a lead classification point of view: they should add to a lead’s score!
Now, making a custom check for this, even when indexing unique IDs, can be a bit clunky, since there are three conditions to check:
- Same company
- Same title
- Different URL
But since I applied some conditional formatting to the spreadsheet, that highlights titles and companies appearing more than once, I thought of a different approach: what if the script could check the colors?
It should look at rows in which BOTH company name and titles are colored.

The condition by itself is not sufficient, as the tricky faces in the screenshot suggest: the title might be repeated by another company, like here the 1st one having the same job title as the 3rd one.
So we want cases where this occurs twice or more, to the same couplings.
Suddenly, the logic seems similar to the one of word frequency extraction, described in pt. 2!
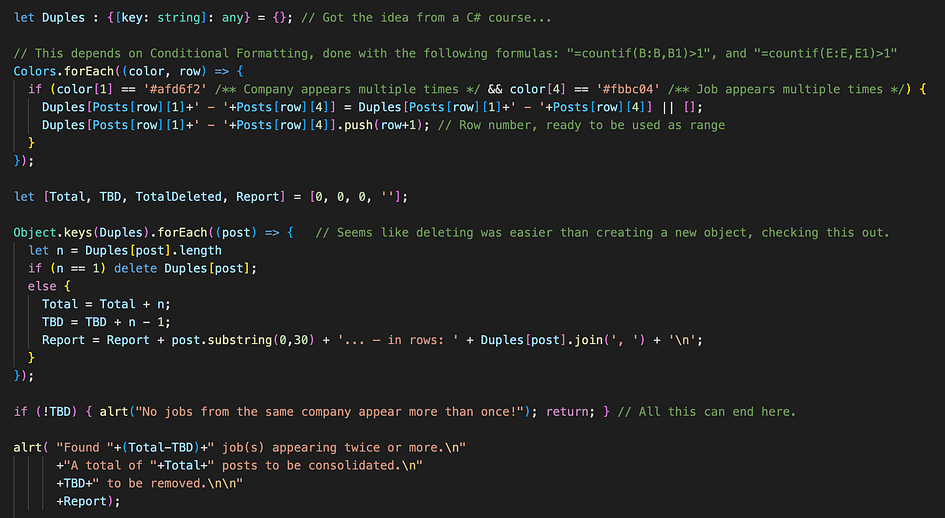
If you can look past the aggressive commenting, you see the condition of the colors being those of the previous screenshot at the same time, is used to build a “Duples{}” object in a very similar fashion as the wordFreq{} object used for skill extraction in pt. 2, with two main differences:
- The keys are named after both the company name and job name combined. (To count together only those where BOTH match.)
- The values are actually arrays, where we push “row+1”, which converts the index of the forEach loop into the actual row number where the condition is found. (Loops count from 0, Google Sheet counts from 1.)
This way, we end up with {‘company — job title’: [row1, row2, …]}
Or do we? Not right away! The second block of code, where we go through the keys of this new object, is where we filter out the cases where we found only single occurrences (false cases like the screenshot above), by checking the length of the rows array (called “post” in this loop), and straight up delete key-value couples with only 1 element, as they have no interest for us.
Instead, for each case where the length of the array (which is the number of rows respecting the condition) is 2 or more, we record a Total number of posts that will be consolidated, and the number of those to be deleted (TBD), for reporting purposes. (The nice popup message, below).
Work is not finished though. Apart from reporting, we wanna make sure we keep something of the latest post, merged into the first one (we want to keep the old post where it is, but with updated info from the newest one.)
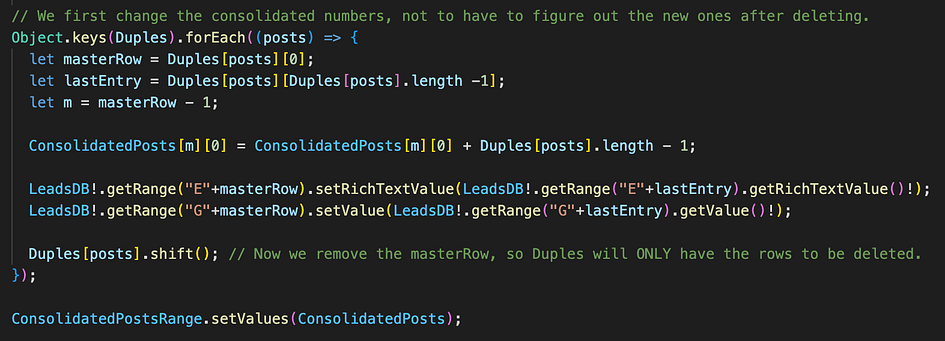
Here (if we hit “OK” previously) we proceed to the real work done by this function: another forEach loop on the keys of the object, which will record a “masterRow” as the first entry found (which as mentioned should be the one we want to keep), and a lastEntry, which is always the most recent.
Then we update the number of a column called “ConsolidatedPosts”, within the masterRow (corrected here in a contrary way because we go from actual row number to position in an array, so minus 1) adding the number of elements minus 1 (not to count twice the original row we keep.)
Then we have to copy one by one (a slow process… In milliseconds, at least 😏) relevant fields from lastEntry into masterRow.
Finally, we shift() the array of the entry in question, which removes the first element: we don’t need the masterRow anymore after it’s updated: we only need the rows to be deleted!
And finally finally we just write the values of ConsolidatedPosts all at once, which is much faster than doing those one by one.
Programmatically deleting rows & pseudo-trash bins
At this point we can delete. But wait! I don’t want permanent deletion: I fetched this data, so I wanna keep copies archived. 🤓 — I want a trash bin!
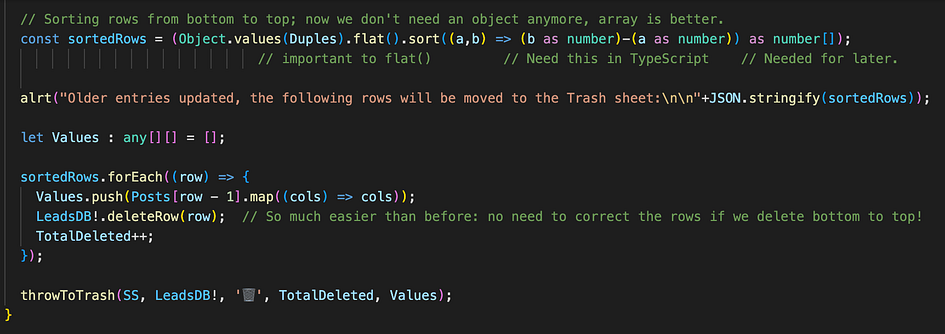
At the cost of copying the rows to be deleted into the unimaginatively-called Values[][] array, I can invoke my custom “throwToTrash(…)” function.
A few words about row deletion, which you might have noticed comes after sorting of the array… A simple loop to delete could have sufficed, right?
Wrong! For each deletion, all the rows below it will shift, and if we don’t adjust for this, on the next iteration we delete a wrong one, and then cascade like this till we delete all the wrong rows except the first one… (Thanks Google for the Restore Version feature!! 😅)
At first, I figured out a way to adjust for this, which was clunky as hell, because sometimes you have to adjust, sometimes you don’t, depending on where the previous deletion happened: below or above.
Then, looking for better ways to do this on StackOverflow, a kind soul there reminded the whole world to switch on their brain: just sort the rows from bottom to top before deleting, and you don’t have to adjust anything!! 🤯
Back to the trash function, I use it for many purposes, like removing posts from incompatible companies, but without losing track of them. Here it is.
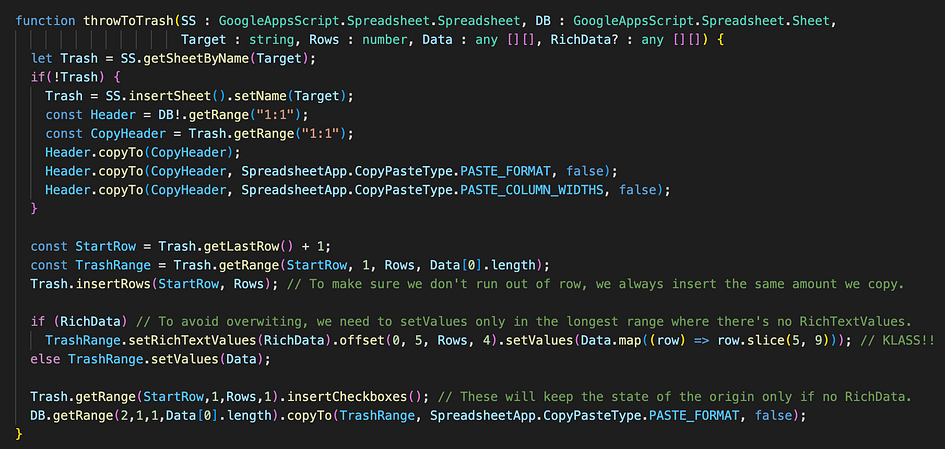
It checks for a sheet called “🗑️”, literally the emoji for the trash bin. 😄
If it finds it, it’s ready to copy the stuff we pass through the function’s arguments (with types specified, so we avoid messing up, thanks to TypeScript!) Otherwise, it creates a news one programmatically, copying the header from the sheet we specify, before proceeding to do the rest.
Here the only neat thing is combining setRichTextValues() (needed for links) and regular setValues() (since I don’t want to format stuff just to make it Rich Text.) It was quite a headache in the beginning of my GAS days!
Because the problem is they will overwrite each other even when they don’t carries values, effectively deleting stuff. So you want to separate the ranges you apply them to.
My solution to this issue in ONE code line [after if(RichData)] inspired me a childish “KLASS!” comment, on the right: it basically chains a call of setValues after RichTextValues, modifying the range in-between, and mapping values to take only a slice of columns.
I confess: this used to take me many lines before… It felt so good to find a way to make it a one-liner!! 😆
What you actually want to read is here!
Once again I got carried away, so I hope the non-coders among you (and the many coders for whom this is easy stuff) skimmed carelessly till here.
While last time the focus was performance (and how sometimes it should not be the focus), this time the lesson is more abstract, and it’s been swimming in my mind for some time, as mentioned in the previous post.
In short: sometimes the UI you want to build is already in front of you!
It tickles my mind every day now: there is so much that can be done, programming on top of programs that are already useful, like Google Sheets. The cases above, of using conditional formatting to help a script, sheet tabs as notification space, or entire sheets for trash collection, are small but valuable examples of this.
But it goes beyond UI, like when I saw I could basically cache stuff on the document/script properties for fast access; there are so many things that can work with/for you, and you just have to connect them.
All in all I feel like I just barely scratched the surface of a new world!

This cloudy (pun intended) thought first came to me when I created my first (and for now only) Chrome Extension for recruitment, which I will talk about in the next post/NOVEL I will write… (I keep postponing it!😅)
It basically has no UI, using Chrome’s UI to do extra stuff on top of the usual: new functionality for UI elements I had for free, and had to use anyway…
This is why last time I closed with the following quote, and I’ll do so again:
We are like dwarfs on the shoulders of giants, so that we can see more than they, and things at a greater distance, not by virtue of any sharpness of sight on our part, or any physical distinction, but because we are carried high and raised up by their giant size.
— Attributed to Bernard of Chartres by John of Salisbury, circa 1159
In the IT world, this is true on so many levels, but I feel like I discovered a “new level” of this: one that is not at the very top of the scale, the user level, but also not at the bottom, the develop-from-scratch level: it’s somewhere inside a seldom-explored middle-ground, where we can squeeze everything out from existing software, and build on top, to actually reach higher levels of productivity than with vanilla stuff, faster than developing from scratch.
Once again, magic made possible by FusionWorks!! 😎